庖丁解LevelDB之数据存储 数据处理与存储支持服务深度剖析
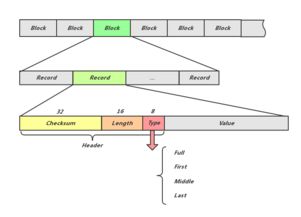
LevelDB作为Google开源的轻量级键值存储引擎,以其高效、可靠的存储特性被广泛应用于各类系统中。其数据存储机制犹如庖丁解牛,精准而高效。本文将深入剖析LevelDB的数据处理流程与存储支持服务,揭示其内部运作的精妙设计。
一、数据写入流程:从日志到持久化
LevelDB的数据写入遵循“先写日志,后写内存表”的原则,确保数据的持久性与一致性。当写入请求到达时,系统首先将操作记录追加到Write-Ahead Log(WAL)中,即使后续进程崩溃,数据也能通过日志恢复。数据被插入到内存中的MemTable(基于跳表实现),提供快速的读写访问。这种设计兼顾了性能与安全,是LevelDB高可靠性的基石。
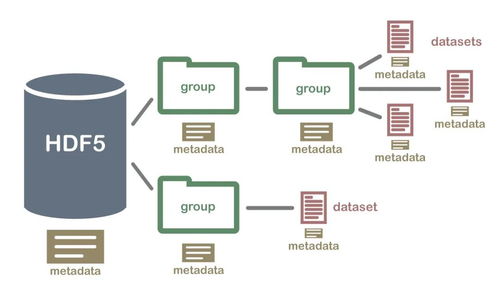
二、内存与磁盘的协同:MemTable与SSTable
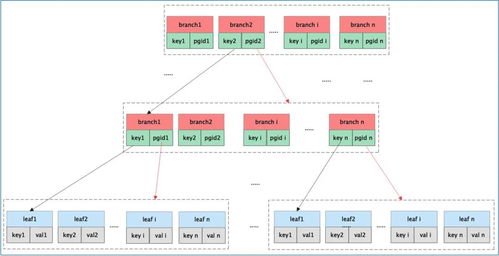
MemTable作为内存数据结构,容量有限。当达到阈值时,LevelDB会将其冻结为Immutable MemTable,并异步压缩转换为磁盘上的Sorted String Table(SSTable)。SSTable按键排序存储,支持高效的范围查询。LevelDB通过分层(Level)组织SSTable,并利用Compaction过程合并和清理旧数据,平衡读写放大问题。这种分级存储策略,实现了数据在内存与磁盘间的动态流转。
三、存储支持服务:缓存、索引与压缩
LevelDB内置多项存储支持服务以优化性能。Block Cache缓存频繁访问的磁盘数据块,减少I/O开销;Bloom Filter作为概率索引,快速判断键是否存在于SSTable中,避免不必要的磁盘扫描;Snappy压缩算法则减小存储空间,提升传输效率。这些服务协同工作,共同构建了一个高效、低延迟的存储环境。
四、故障恢复与一致性保障
LevelDB通过Manifest文件记录元数据变更(如SSTable层级信息),结合WAL日志,确保系统在崩溃后能恢复到一致状态。Compaction过程采用渐进式策略,避免长时间阻塞,同时通过版本控制管理数据快照,支持多线程并发访问。这些机制保障了数据在复杂场景下的完整性与可用性。
精雕细琢的存储艺术
LevelDB的数据存储设计,体现了对细节的极致追求。从日志持久化到分层压缩,从缓存加速到故障恢复,每个环节都经过精心优化。正如庖丁解牛,其核心在于深刻理解数据流动的脉络,以简洁的架构解决复杂的存储挑战。对于开发者而言,掌握这些原理不仅能更好地应用LevelDB,也能为设计高性能存储系统提供宝贵借鉴。
如若转载,请注明出处:http://www.zhaocebao.com/product/62.html
更新时间:2026-06-19 08:11:11