大数据处理工具与支持服务全景盘点
在数据爆炸式增长的时代,高效、可靠的大数据处理工具与支持服务已成为企业数字化转型的核心驱动力。从海量数据的采集、存储、处理到分析与应用,整个技术栈涵盖了众多开源项目与商业解决方案。本文将系统盘点当前主流的大数据处理工具及相关支持服务,为技术选型与架构设计提供参考。
一、 数据处理与计算框架
数据处理框架负责对海量数据进行分布式计算,是大数据技术的核心引擎。
- 批处理框架:
- Apache Hadoop MapReduce:经典的批处理模型,适合处理超大规模数据集,但编程模型相对复杂,延迟较高。
- Apache Spark:当前最主流的统一分析引擎。其基于内存计算的DAG执行引擎,在批处理性能上远超MapReduce,同时通过Spark Streaming(微批)支持流处理,并通过MLlib、GraphX等库支持机器学习与图计算。
- Apache Flink:以流处理为核心设计的引擎,实现了真正的流批一体。其低延迟、高吞吐的特性在实时处理场景中表现卓越,同时其批处理能力也非常强大。
- 流处理框架:
- Apache Storm:早期的低延迟流处理系统,擅长处理无界数据流,保证消息不丢失。
- Apache Kafka Streams:一个轻量级的客户端库,直接利用Kafka集群进行流处理,非常适合构建微服务化的实时应用。
- Apache Samza:与Kafka和YARN紧密集成的流处理框架,强调可插拔性和状态管理。
二、 数据存储与数据库服务
大数据存储不仅要求容量,更强调结构多样性、扩展性与访问性能。
- 分布式文件系统:
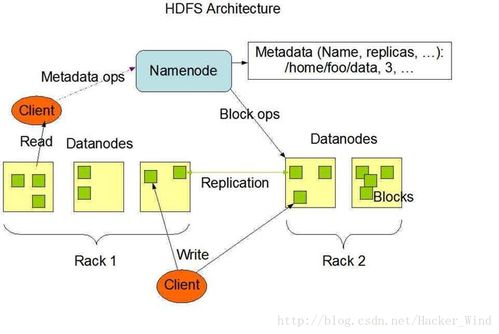
- Hadoop Distributed File System (HDFS):大数据存储的基石,提供高容错性、高吞吐量的数据访问,适合存储海量非结构化与半结构化数据。
- NoSQL数据库:
- 键值存储:如 Redis(内存型)、Apache Cassandra(宽列存储,高可用与线性扩展)、Amazon DynamoDB(托管服务)。适用于会话存储、高速缓存等场景。
- 文档数据库:如 MongoDB、Couchbase。以JSON格式存储,模式灵活,适合内容管理和用户数据存储。
- 列式数据库:如 Apache HBase(基于HDFS)、Google Bigtable。适合需要随机、实时读写访问超大规模数据集的场景。
- 图数据库:如 Neo4j、Amazon Neptune。专门用于存储和查询实体间复杂关系网络。
- 数据仓库与湖仓一体:
- Apache Hive:构建在Hadoop之上的数据仓库工具,提供SQL查询能力。
- Snowflake、Amazon Redshift、Google BigQuery:云原生数据仓库,完全托管,强调弹性扩展与高性能分析。
- Databricks Lakehouse Platform、Apache Iceberg、Delta Lake:代表“湖仓一体”架构,在数据湖的低成本存储上实现数据仓库的数据管理与ACID事务特性。
三、 数据集成与工作流调度
这些工具负责数据的移动、转换与任务编排。
- 数据采集与集成:
- Apache Kafka:分布式流数据平台,作为实时数据管道和消息系统的核心。
- Apache Sqoop:用于在Hadoop和关系型数据库之间高效传输批量数据。
- Apache Flume、Logstash:用于高效收集、聚合和移动大量日志数据。
- Debezium:基于日志的变更数据捕获(CDC)工具。
- 工作流调度:
- Apache Airflow:以代码定义、调度和监控工作流的平台,功能强大,社区活跃。
- Apache Oozie:Hadoop生态内的老牌工作流调度器,与Hadoop栈集成紧密。
- Dagster、Prefect:现代的数据编排平台,更注重开发体验、数据感知和可观测性。
四、 云端全托管支持服务
云厂商提供了免运维、即开即用的全托管服务,大幅降低了大数据平台的管理复杂度。
- 计算服务:
- Amazon EMR、Google Dataproc、Azure HDInsight:托管式的Hadoop/Spark集群服务,可快速部署生态组件。
- AWS Glue:无服务器的ETL服务,包含数据目录、作业调度等功能。
- 存储服务:
- 对象存储:如 Amazon S3、Azure Blob Storage、Google Cloud Storage,已成为数据湖事实上的标准存储层。
- 托管数据库:如前文提到的 DynamoDB、BigQuery、Azure Cosmos DB(多模型数据库)。
- 流数据服务:
- Amazon Managed Streaming for Kafka (MSK)、Confluent Cloud(基于Kafka的托管服务)、Google Pub/Sub。
五、 选型建议与趋势展望
选型时需综合考虑数据规模、处理延迟要求(实时/批处理)、数据类型、团队技能栈及成本(开源自建 vs. 云托管)。当前趋势明显指向 云原生、存算分离、流批一体、湖仓融合。以Spark/Flink为核心的计算引擎,搭配S3等对象存储作为数据湖,上层通过Iceberg/Hudi等表格格式进行管理,并通过Airflow等工具进行编排,正成为构建现代数据平台的流行架构。完全托管的云服务让企业能更专注于数据价值挖掘而非基础设施运维。
大数据技术生态丰富且迭代迅速。理解各类工具的核心特性和适用场景,结合自身业务需求与云战略进行组合与集成,是构建高效、敏捷数据能力的关键。
如若转载,请注明出处:http://www.zhaocebao.com/product/68.html
更新时间:2026-06-19 11:46:27