数据管理与运维 构建可靠高效的数据基石
在数据科学实践中,高效、可靠的数据管理与运维是驱动洞察与决策的底层引擎。本课程聚焦数据管理与运维的核心环节,旨在为您构建一个清晰、实用的行动框架。
一、 数据分层:构建清晰的数据架构
数据分层是组织数据的战略性方法,旨在优化存储成本、访问效率和治理能力。常见的分层模型包括:
1. 原始层(Raw/Landing Zone):存储未经处理的原始数据,保留数据全貌,为回溯和分析提供源头。
2. 处理层(Cleansed/Processing Zone):在此进行数据清洗、转换、集成,提升数据质量与一致性,为分析做好准备。
3. 应用层(Curated/Application Zone):存储面向业务场景的聚合数据、模型结果与核心指标,直接支持报表、API和服务调用。
4. 归档层(Archival Zone):存储低频访问的历史数据,采用低成本存储方案,满足合规与审计要求。
合理的分层策略能平衡性能、成本与敏捷性,是数据资产化的第一步。
二、 质量运维与元数据管理:确保数据的可信与可知
数据质量运维:这是一个持续的过程,而非一次性项目。它涵盖:
质量规则定义:设定完整性、准确性、一致性、时效性等维度的校验规则。
- 监控与告警:自动化监控数据管道,在质量规则被触发时及时告警。
- 根因分析与修复:建立流程,快速定位质量问题源头并实施修复。
- 质量报告:定期生成数据质量健康度报告,量化信任水平。
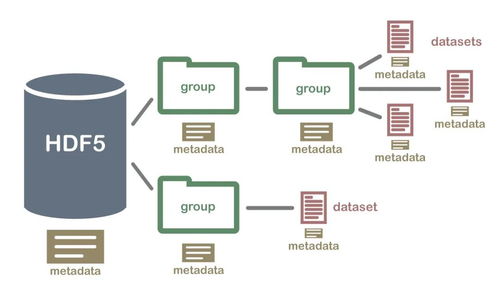
- 元数据管理:元数据是“关于数据的数据”,是数据资产的导航图与说明书。管理重点包括:
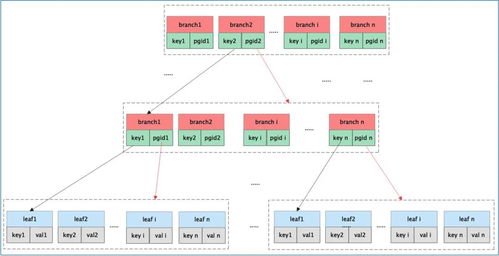
- 技术元数据:如表结构、ETL过程、血缘关系(数据从源到目标的流转路径)。
- 业务元数据:如指标定义、业务术语、数据负责人。
* 操作元数据:如数据更新频率、访问日志。
有效的元数据管理能极大提升数据发现、理解、协作与治理的效率。
三、 数据剖析、故障转移与迁移:保障数据的可用与流动
数据剖析:在集成或使用新数据源前,系统性地分析其内容、结构和质量,以评估其适用性并发现潜在问题。
故障转移:为确保关键数据服务的高可用性,需设计容灾方案。当主系统发生故障时,能自动或手动切换到备用系统,保证业务连续性。
* 数据迁移:在系统升级、平台切换或业务重组时,制定周密的迁移计划,包括数据映射、清洗、验证和回滚策略,确保数据在迁移过程中的完整性与一致性。
四、 数据安全:定义与实施防护体系
数据安全是管理与运维的生命线,需贯穿数据全生命周期。
- 定义:明确敏感数据分类分级标准(如公开、内部、机密、绝密),并据此制定差异化的安全策略。
- 实施:构建多层次防护体系:
- 访问控制:基于角色(RBAC)或属性(ABAC)实施最小权限原则。
- 加密:对静态数据和传输中数据实施加密。
- 脱敏/匿名化:在开发、测试或对外共享时保护敏感信息。
- 审计与监控:记录所有数据访问与操作行为,便于追溯与合规检查。
五、 报表与服务:流程与概念
将数据处理成果有效交付给最终用户,需要清晰的流程与概念:
- 报表开发流程:需求分析 → 数据模型设计 → ETL/ELT开发 → 可视化开发 → 测试与发布 → 运维与优化。
- 服务化概念:将数据能力(如查询、模型预测)封装成标准API,供其他系统调用,实现数据产品的敏捷交付与复用。
六、 数据处理和存储支持服务:技术选型与运维
这是整个体系的物理基础,涉及:
- 数据处理服务:批处理(如Apache Spark)、流处理(如Apache Flink)、查询引擎(如Presto/Trino)的选择与集群运维。
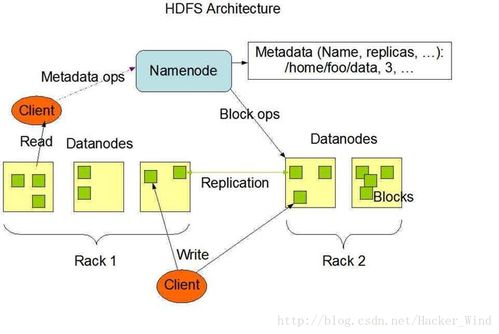
- 数据存储服务:根据数据分层需求,选配对象存储(如AWS S3)、数据仓库(如Snowflake)、数据湖(如Delta Lake)、NoSQL数据库等,并管理其容量、性能与成本。
****
卓越的数据管理与运维,是将原始数据转化为可信、可用、安全战略资产的核心工程。它要求我们不仅关注技术工具,更要建立系统的流程、明确的规范和协同的文化。通过构建分层清晰的架构、实施严格的质量与安全控制、保障高可用的服务,数据团队才能为数据科学分析和业务创新提供坚实、高效的基石,真正释放数据价值。
如若转载,请注明出处:http://www.zhaocebao.com/product/63.html
更新时间:2026-06-19 22:10:30