大数据基础 数据存储组件及处理与存储支持服务概览
在当今数据驱动的时代,大数据技术已成为企业获取洞察、优化决策的核心引擎。一个健壮的大数据体系架构依赖于高效、可扩展的数据存储组件,以及强大的数据处理与存储支持服务。本文将系统性地介绍大数据领域的关键数据存储组件,并阐述支撑其高效运行的处理与存储服务。
一、 核心数据存储组件
大数据存储组件根据数据特性、访问模式和业务需求,主要分为以下几类:
- 分布式文件系统
- 代表:HDFS (Hadoop Distributed File System)
- 核心思想:将超大文件分割成块(Block),分散存储在多台廉价商用服务器上,提供高吞吐量的数据访问。它遵循“一次写入,多次读取”的模式,非常适合存储海量原始数据,是Hadoop生态的基石。
- 特点:高容错性、高吞吐量、可线性扩展、成本低廉。
2. NoSQL数据库
为应对海量半结构化、非结构化数据的高并发读写需求而诞生,放弃了传统关系型数据库的部分特性(如强一致性、复杂事务),以换取更高的扩展性和灵活性。
- 键值存储 (Key-Value Store):如 Redis(内存型,极高性能)、DynamoDB(云托管)。通过唯一的键来访问数据,简单高效,常用于缓存、会话存储。
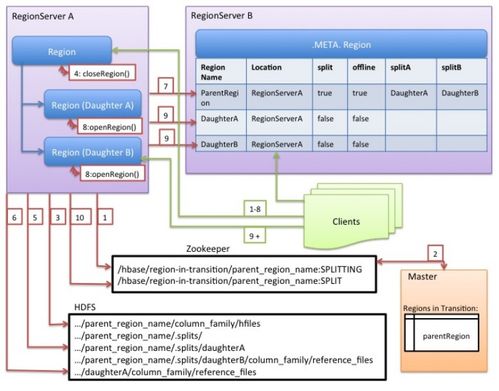
- 列式存储 (Wide-Column Store):如 HBase(基于HDFS)、Cassandra。数据按列族存储,适合稀疏数据,支持海量数据的随机、实时读写。
- 文档数据库 (Document Store):如 MongoDB、Couchbase。以JSON/BSON等格式存储半结构化文档,模式灵活,易于开发。
- 图数据库 (Graph Database):如 Neo4j。专门存储实体(节点)和关系(边),擅长处理复杂的关联查询,如社交网络、推荐系统。
3. NewSQL数据库与分布式SQL引擎
试图兼顾NoSQL的扩展性与传统SQL数据库的ACID事务和强一致性。
- NewSQL:如 Google Spanner、TiDB。重新设计的分布式关系型数据库。
- 分布式SQL引擎:如 Apache Hive(将SQL转化为MapReduce/Tez/Spark作业)、Presto/ Trino、Impala(MPP架构,交互式查询)。它们本身不直接存储数据,而是作为计算引擎对底层HDFS或对象存储中的数据执行快速SQL查询。
- 对象存储
- 代表:AWS S3、阿里云OSS、MinIO。
- 核心思想:将数据作为不可变的对象(Object)连同元数据一起存储在一个扁平的命名空间中(桶Bucket)。通过RESTful API访问。
- 特点:无限扩展、高耐久性、成本低廉,已成为云上数据湖(Data Lake)的事实标准存储。
- 消息队列/日志存储
- 代表:Apache Kafka。
- 角色:虽然主要作为实时数据流平台,但其持久化、分区的提交日志(Commit Log)架构使其成为出色的流数据“存储”中间件,用于解耦生产者和消费者,缓冲海量事件数据。
二、 数据处理与存储支持服务
仅有存储组件还不够,需要一系列服务来管理、优化和保障数据生命周期的各个环节。
- 数据处理与计算框架
- 批处理:Apache Hadoop MapReduce(开创性,但较慢)、Apache Spark(内存计算,性能卓越,支持批流统一)。
- 流处理:Apache Storm(早期)、Apache Flink(低延迟、高吞吐、状态精确一次处理)、Spark Streaming(微批处理)。
* 交互式分析:Presto/Trino、Apache Druid(实时OLAP)。
这些框架是数据的“加工厂”,从存储组件中读取数据,进行计算分析,再将结果写回存储。
- 资源管理与协调服务
- 资源管理:Apache YARN(Hadoop 2.0+的核心,负责集群资源调度与管理)、Kubernetes(容器编排,日益成为大数据工作负载的新调度平台)。
- 协调服务:Apache ZooKeeper(提供分布式一致性服务,如配置管理、命名服务、分布式锁,是HBase、Kafka等组件的依赖)。
- 数据编排与元数据管理
- 数据编排:Apache Airflow、DolphinScheduler。用于定义、调度和监控复杂的数据处理工作流(Pipeline)。
- 元数据管理:Apache Atlas、DataHub。提供数据血缘(Lineage)、分类、治理功能,帮助理解数据的来源、变化和流向,是数据治理的核心。
- 存储优化与缓存服务
- 存储格式:列式存储格式如 Parquet、ORC,能极大提升查询性能并降低存储成本。
- 数据压缩:如Snappy、LZO、Zstandard,节省存储空间和网络I/O。
- 缓存层:如 Alluxio(内存速度的虚拟分布式存储系统),在计算框架和底层存储(如S3、HDFS)间提供缓存加速层。
5. 云上托管服务
云厂商(AWS, Azure, GCP, 阿里云等)提供了上述几乎所有组件的全托管服务(如EMR、Databricks、BigQuery、Cosmos DB),极大降低了运维复杂度,让用户更专注于数据价值挖掘。
###
大数据的数据存储生态是多元且互补的。HDFS/对象存储常作为数据湖的持久化层;NoSQL数据库应对特定场景的高性能读写;分布式SQL引擎提供便捷的数据查询入口;而Kafka则连接实时数据流。这一切都由YARN/K8s等资源管理器调度,由Airflow等工具编排任务,并由Atlas等平台治理。理解各组件的定位与协同关系,是构建高效、可靠大数据平台的基础。在实际架构选型中,需紧密结合数据特征、业务场景、性能要求与成本约束进行综合决策。
如若转载,请注明出处:http://www.zhaocebao.com/product/53.html
更新时间:2026-06-19 16:06:37